¡Tu carrito está actualmente vacío!

Los modelos de lenguaje como Claude, desarrollados por Anthropic, no son programados directamente por humanos, sino que aprenden de enormes cantidades de datos.
Durante su entrenamiento, desarrollan estrategias propias para resolver problemas, estrategias que los desarrolladores no pueden interpretar completamente.
Esto plantea una pregunta clave: ¿Cómo piensan realmente estos modelos de lenguaje?
Preguntas clave sobre Claude
Comprender el pensamiento de modelos como Claude podría mejorar su control y fiabilidad. Algunas interrogantes fundamentales son:
- Claude habla varios idiomas. ¿Utiliza un «lenguaje del pensamiento» universal?
- Escribe palabra por palabra. ¿Predice solo la siguiente palabra o planifica con antelación?
- Explica su razonamiento. ¿Es fiel a su proceso interno o inventa explicaciones plausibles?
Un «microscopio» para la IA
Inspirados en la neurociencia, investigadores de Anthropic implementaron herramientas para analizar el pensamiento de la IA. Un estudio reciente aplicó esta metodología a Claude 3.5 Haiku, revelando aspectos inesperados:
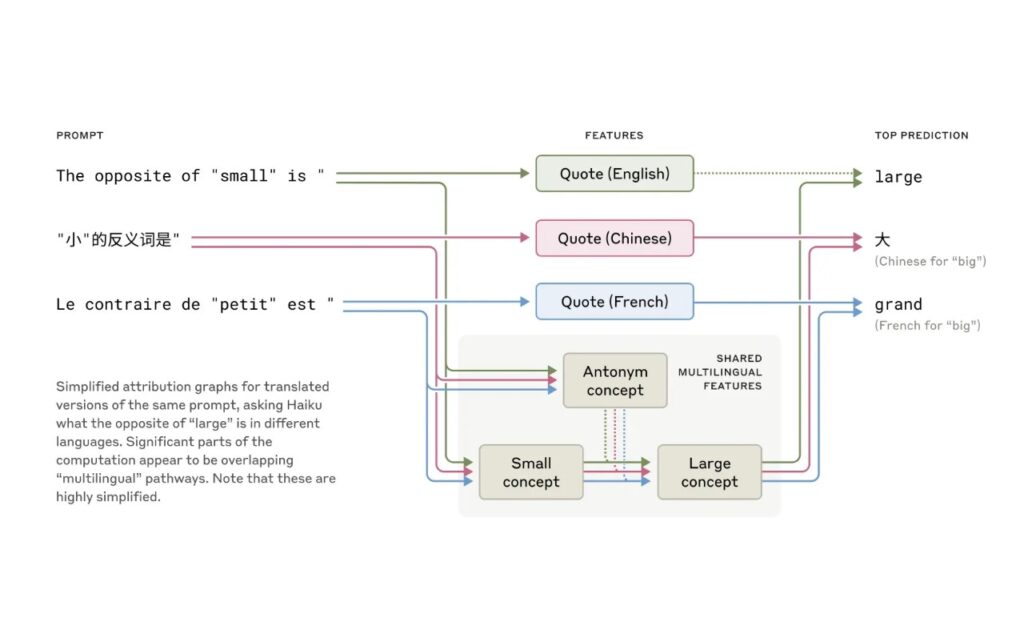
- Pensamiento multilingüe: Claude parece operar en un espacio conceptual común antes de traducir pensamientos a idiomas específicos.
- Planificación avanzada: Aunque escribe palabra por palabra, planifica en anticipación, especialmente en tareas como la poesía con rima.
- Explicaciones a medida: En problemas matemáticos, a veces «inventa» razonamientos en lugar de seguir un proceso lógico real.
El enigma del pensamiento en los modelos de lenguaje
El análisis reveló comportamientos sorprendentes.
Se esperaba que Claude no planificara sus respuestas, pero se descubrió que lo hace.
En pruebas de alucinación, hallaron que su tendencia natural es evitar especular, salvo que ciertos mecanismos inhiban esta respuesta predeterminada.
Los descubrimientos no solo mejoran la comprensión de la IA, también pueden aplicarse en otras áreas, como la genómica o la imagenología médica.
También podrían contribuir al desarrollo de interfaces cerebro-computadora más eficaces, al generar que los modelos de IA se comuniquen de manera más intuitiva con humanos.
No obstante, el estudio también reconoce las limitaciones de estas herramientas, que requieren mejoras para escalar a modelos más complejos.
La interpretación del pensamiento de la IA sigue siendo un desafío técnico, ya que la cantidad de datos procesados es inmensa y su estructura interna no siempre es comprensible.
Hacia una IA transparente
A medida que los modelos de IA se vuelven más sofisticados, entender sus mecanismos internos será esencial para garantizar su fiabilidad.
La investigación en interpretabilidad no solo es un reto científico, sino una necesidad para asegurar que la IA se alinee con los valores humanos y merezca nuestra confianza.
Avanzar en esta dirección permitirá que la IA sea utilizada con mayor seguridad en ámbitos sensibles, como la toma de decisiones médicas o la automatización de procesos críticos.
Con información de Anthropic.
Tagged in :
Más entradas

IA y NASA: Predicción de eventos solares
.
La inteligencia artificial ayuda a predecir eventos solares y proteger satélites de posibles interrupciones.
Google renueva Play Store con IA y nuevas funciones
.
Google anunció una importante actualización de su Play Store, orientada a mejorar la interacción de sus más de 4 mil millones…
Meta lanza Hyperscape convirtiendo espacios en mundos virtuales
.
En Meta Connect, la compañía de Mark Zuckerberg presentó varias actualizaciones sobre el metaverso, resaltando el lanzamiento de Hyperscape.